Exploring OpenCL memory management
In this post, I hope to give a high level understanding of OpenCL's Memory Mechanisms
The basics
Firstly, its important to have a basic understanding of the hardware involved. Keeping it simple, each OpenCL device represents a different set of hardware, each with its own RAM. My own laptop has a 16GB CPU RAM, and 6GB VRAM
Now, at the heart of C, we have pointers, without them well, you can’t really get much done in C. The pointers we conventionally use are pointers to CPU RAM.
So what would happen if you try to pass a CPU Pointer to the GPU? Well, of course, it wont work, the GPU simply segfaults, as it cannot understand the pointer given to it. But we still need to use pointers, we can’t just abandon them. So how do we do this?
Buffers
At the simplest level, we have OpenCL Buffers. These buffers are chunks of memory allocated on the OpenCL device as well as on host memory.
cl_mem clCreateBuffer(
cl_context context,
cl_mem_flags flags,
size_t size,
void *host_ptr,
cl_int *errcode_ret)
Creating a buffer is easy, its figuring out what kind of buffer you need that is important.
Broadly speaking there are 3 types of buffers based on the flags passed:
CL_MEM_USE_HOST_PTR
This tells OpenCL to use the host pointer provided as the underlying memory on host.
CL_MEM_COPY_HOST_PTR
This flag tells OpenCL to make a new buffer and fill it with the memory pointed to by host pointer.
CL_MEM_ALLOC_HOST_PTR
This one is the same as CL_MEM_USE_HOST_PTR, but the allocation of host pointer is also done by OpenCL
But which one should you use? Well, if you desire a zero copy buffer, i.e. create a buffer without copying memory, especially memory on host, then CL_MEM_USE_HOST_PTR(if you have the memory already initialised) or CL_MEM_ALLOC_HOST_PTR(if you plan to initialise the buffer afterward) The concept of a zero copy buffer is super helpful when you are targeting the same host CPU as an OpenCL device.
I mean, you already have the data in CPU RAM, why would you make another copy in CPU RAM by creating a new buffer?
Literacy for Buffers
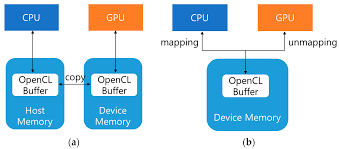
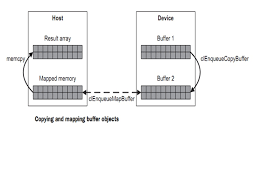
The above is enough when you are operating on the same device, which is seldom the case with OpenCL. But when you work with GPUs, you need to get the memory into GPU VRAM somehow.
And this is impossible(maybe) without copying the data over.
So how do you copy the data over to GPU VRAM? Well, after allocating a buffer as seen before, OpenCL will try to recreate the host side buffer on the device as well.
But when you update the host side buffer(like reading in input), youd want it to reflect on device as well. Similary, when your device is done processing, you need to get the output from device memory to host memory.
There are two main ways to do this:
Read/Write Buffer
You have a buffer on host memory and on device memory that mirror each other.
cl_int clEnqueueReadBuffer(
cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_read,
size_t offset,
size_t size,
void* ptr,
cl_uint num_events_in_wait_list,
const cl_event* event_wait_list,
cl_event* event);
cl_int clEnqueueWriteBuffer(
cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_write,
size_t offset,
size_t size,
const void* ptr,
cl_uint num_events_in_wait_list,
const cl_event* event_wait_list,
cl_event* event);
OpenCL provides Read/Write commands to force overwrite of one buffer over the other, and in this way, data transfer is achieved.
Map/Unmap Buffer
There is a single buffer on device memory, that is presented to CPU when demanded So “mapping” a buffer will bring it from device memory into host RAM. Then any changes made will be saved in host RAM. Finally, once done with changes, you may “unmap” the buffer, which writes all changes made back to device memory
void* clEnqueueMapBuffer(
cl_command_queue command_queue,
cl_mem buffer,
cl_bool blocking_map,
cl_map_flags map_flags,
size_t offset,
size_t size,
cl_uint num_events_in_wait_list,
const cl_event* event_wait_list,
cl_event* event,
cl_int* errcode_ret);
cl_int clEnqueueUnmapMemObject(
cl_command_queue command_queue,
cl_mem memobj,
void* mapped_ptr,
cl_uint num_events_in_wait_list,
const cl_event* event_wait_list,
cl_event* event);
In this way, data transfer is achieved
To map or not to map?
To be honest, performance differences are very minute, atleast from my tests with the gnuastro library. However Map and Unmapping makes a world of difference as compared to Read/Write when it comes to simplicity
The problem with buffers
No matter what you do, when working with buffers, you always end up copying the data For example, you load an image into CPU RAM, but actually want to work with it on the GPU. So, you end up copying the image into GPU RAM. In the end, you process the same data twice, once while loading and once while copying
For small images(2000 x 2000) this is barely noticeable But gnuastro, and the people using gnuastro deal with astronomical images of incredibly large sizes(i’ve heard 30GB just for one image).
So, most certainly, any time you save by using parallelised processing on the GPU, is lost and maybe even worsened by the data transfer times. Then, using the GPU is almost pointless, unless you use the same data over and over again
“Well, cant I just load the data on the GPU directly?” Thats not possible, atleast not to my knowledge. This is the tradeoff with GPUs. On a CPU, you have 4/8/16 highly specialised and capable cores(math, I/O), while on the GPU you have 1000s of some very primitive cores only capable of basic operations(only math, no I/O) So you always have to load it into CPU RAM first and then go to GPU RAM.
So how can we fix this problem? Well, one of the options is to use Shared Virtual Memory(OpenCL SVM), which enables the GPU to directly access CPU RAM and play with CPU pointers.
However, I still have yet to test SVM in the context of gnuastro, to see if its useful. Besides, SVM also fixes the problem of structs containing pointers(for another post). Documentation for OpenCL is already scarce, and to add insult to injury, documentation on OpenCL SVM is even more scarce. But I like the challenge…